맞춤형 CPU, AI 가속기와 자사 제품 연동, ‘NV링크 퓨전’ 공개
젠슨 황, ‘컴퓨텍스2025’서 “칩 업계 망라 ‘NV링크 생태계’ 구축”
타사 GPU 간, CPU 간 직접 통신 프로그램, “엔비디아 독접 기술”
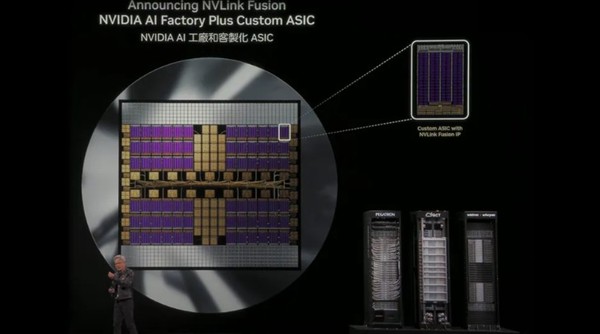
[애플경제 이지향 기자] 최강자의 여유랄까. 엔비디아는 대만 타이베이에서 열린 ‘컴퓨텍스 2025’에서 많은 칩 제조업체들과 연동할 수 있는 칩 생태계 프로그램인 NV링크 퓨전(NVLink Fusion)을 공개했다.
엔비디아의 NV링크는 GPU 간, 그리고 CPU 간 직접 통신을 위한 독점적인 상호 연결 기술이다.
이날 무대에 선 엔비디아 CEO 젠슨 황은 일단 데이터센터나 기업용 AI 등을 중심으로 다양한 발표를 진행했다. 그러나 이날 핵심은 엔비디아의 고객사들과 파트너가 NV링크 기술을 활용해 맞춤형 ‘랙 스케일’ 설계를 구축할 수 있도록 지원하는 새로운 NV링크 퓨전(Fusion) 프로그램이었다.
이 프로그램을 통해 시스템 설계자는 랙 스케일 아키텍처에서 엔비디아 제품과 함께 타사 CPU나 가속기를 활용, 생산성을 한껏 높일 수 있다는 설명이다.
엔비디아는 이를 위해 이미 퀄컴과 후지쯔 등 여러 파트너사를 확보했으며, 이들은 해당 NV링크 기술을 자사 CPU에 통합할 예정이다. 퀄컴은 최근 자체 맞춤형 서버 CPU를 시장에 출시한다고 밝혔다. 자세한 내용은 아직 전해지지 않았지만, 역시 NV링크 생태계와의 파트너십을 통해 퀄컴의 새로운 CPU는 빠르게 확장하는 엔비디아의 AI 생태계에 발맞춰 나갈 수 있을 것이란 전망이다.
후지쯔 또한 메모리 위에 3D 적층 CPU 코어를 탑재한 144코어의 거대한 모나카(MONAKA) CPU를 시장에 출시하기 위해 노력해 왔다. 후지쯔의 차세대 프로세서인 ‘FUJITSU-MONAKA’는 2나노미터 공정의 Arm 기반 CPU로서, 전력 효율을 극대화하는게 목표다.
NV링크 퓨전은 또 맞춤형 AI 칩(가속기)으로도 확장될 예정이다. 엔비디아는 이미 마벨(Marvell), 미디어텍(Mediatek)을 비롯한 여러 실리콘 업체들과, 시놉시스(Synopsys), 케이던스(Cadence) 등 칩 소프트웨어 설계 업체들을 NV링크 퓨전 생태계에 참여시켰다.
엔비디아는 미디어텍, 마벨, 알칩 등 설계 업체의 ‘ASIC’과 같은 맞춤형 가속기도 도입했다. 이에 엔비디아의 그레이스 CPU와 함께 작동하는 또 다른 맞춤형 AI 가속기들을 지원할 수 있게 되었다. 아스테라 랩스 또한 NV링크 퓨전 상호 연결을 위해 이 생태계에 참여했다. 칩 제조 소프트웨어 공급업체인 케이던스와 시놉시스 또한 강력한 설계 도구와 IP 세트를 제공하기 위해 함께 참여했다.

NV링크 퓨전 프로그램은 훨씬 더 광범위하다. 이는 NV링크 연결을 통해 랙 스케일 아키텍처에서 대규모 확장을 하거나, 확장 애플리케이션을 지원하기도 한다.
NV링크 퓨전은 더 나아가서, 퀄컴이나 후지쯔가 자사 CPU와 인터페이스를 활용하여 생산성을 크게 높일 수 있도록 했다. NV링크 기능은 컴퓨팅 패키지 옆에 위치한 칩렛에 통합되어 있다.
NVLink는 엔비디아가 AI 워크로드에서 우위를 점할 수 있었던 핵심 기술 중 하나였다. 이를 통해 AI 서버에서 GPU와 CPU 간의 통신 속도를 한껏 높일 수 있다. 이는 확장성, 즉 최고의 성능과 전력 효율을 높이는 가장 큰 요소이므로, 엔비디아의 시장 장악의 결정적 요소이기도 했다.
기존 PCIe 인터페이스보다 훨씬 더 넓은 대역폭과 탁월한 지연 시간을 제공한다. 또한 검증된 PCIe 전기 인터페이스를 활용하면서도 최대 14배 높은 대역폭임을 과시하고 있다.
엔비디아는 여러 세대의 제품에 걸쳐 NV링크의 성능을 향상시켜 왔다. 특히 맞춤형 NV링크를 위해 스위치 실리콘을 추가함으로써 이를 단일 서버 노드가 아닌 랙 스케일 아키텍처로 확장할 수 있었다. 이를 통해 “대규모 GPU 클러스터가 AI 워크로드를 동시에 처리할 수 있도록 했다”는 설명이다.
이같은 NV링크의 강점은 AMD와 브로드컴과 같은 경쟁사들이 쉽게 따라잡지 못할 핵심적인 강점으로 자리 잡았다.
하지만 NV링크는 엔비이아의 독점 인터페이스다. IBM과의 초기 협력을 제외하고는 이 기술을 자사 실리콘을 사용하는 제품에만 적용해 왔다.
2022년에 엔비디아는 업계 표준인 Arm의 ‘AMBA CHI’ 및 ‘CXL 프로토콜’을 활용해, 다른 기업들이 자체 칩으로 엔비디아 GPU와의 통신을 용이하게 할 수 있도록 했다. 즉 다른 회사 칩끼리 연결하는 C2C(Chip-to-Chip)기술이다.