클로드, 챗GPT-4o, 제미니 등 무료 AI와 비슷하거나 높아
o1-프리뷰 등 유료 구독 모델보다는 상당히 뒤처져
“IQ와 달리 사용자 만족도면에선 어느 모델보다 높아”
[애플경제 전윤미 기자] 딥시크 충격이 어느 정도 가실 법 하지만, 글로벌 벤치마크에선 다시 딥시크와 챗GPT를 비교하는 모습이 이어지고 있다. 특히 유명 벤치마크인 ‘맥시멈 트루스’는 나름의 정밀한 IQ테스트를 실시했다. 그 결과 “딥시크는 챗GPT-o1만큼 똑똑하지 않다. 단지 딥시크 IQ는 오픈AI의 무료 제품과 맞먹는 수준일 뿐”이라며 “그러나 (인간이 평가하는) 사용자 만족도에선 딥시크가 낫다”는 결론을 내려 주목된다.
딥시크, 출시 초기 ‘o3와 버금’ 평가와 상반돼
이는 이제까지 o1은 물론, o3-미니와 맞먹고 o3-미니 하이보다 뒤지는 정도라는 평가와 상반된 것이어서 주목된다. 맥시멈 트루스는 평소 정밀한 시험과 측정으로 공신력을 얻고 있는 곳이어서 더욱 관심을 끌고 있다.
맥시멈 트루스는 “딥시크는 사용자가 AI 답변에 대해 순위를 매기는 챗봇 분야에서도 챗GPT-4o와 거의 동률을 이루고 있다.”면서도 “하지만 순수 지능 측면에서 어떤 성과를 보일까? 이제 IQ 테스트를 실행해 보았다”며 이같이 밝혔다.
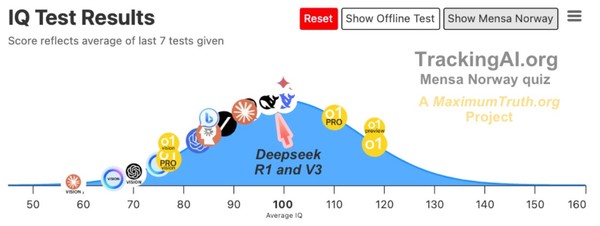
이에 따르면 공개된 IQ 테스트에서 딥시크는 모든 무료AI와 비슷한 수준이지만, 유료 사용자를 위한 오픈AI 모델보다는 크게 뒤처진다. 맥시멈 트루스의 벤치마크 사이트 ‘TrackingAI.org’는 이를 위한 IQ 테스트, 즉 ‘멘사 노르웨이’ 방식을 적용했다.
그 결과 딥시크의 V3, R1 두 모델은 클로드, 챗GPT-4o, 제미니 어드밴스트 등 무료 AI와 동등하거나, 때론 더 뛰어났다. 그러나 o1-프리뷰와 같은 오픈AI의 유료 구독 모델보다는 상당히 뒤처져 있다. “중국은 아직 그 수준에는 미치지 못하고 있다”는 평가다.
온라인 어디에도 없는 ‘질문’ 자료 적용
정밀한 테스트를 위해 맥시멈 트루스는 ‘Jurij’라는 멘사 회원과 협력, 온라인 어디에도 존재하지 않는 새로운 질문을 만들었다. 그런 다음 그가 만든 질문을 이 서브스택 구독자에게 제시했고, 새로운 테스트의 점수를 규격화함으로써 사람을 대상으로 한 ‘멘사 노르웨이’ 퀴즈만큼 어렵게 했다. 그 결과는 오프라인에서만 존재하는 IQ 문제에서 딥시크 R1은 모든 무료 모델을 능가하지만, 오픈AI 유료 모델보다는 뒤떨어졌다
.또 온라인에 존재하지 않는 문제를 낸 퀴즈에서 이른바 ‘다재다능’한 것으로 알려진 딥시크 V3는 오프라인 문제에서 겨우 70점을 받았다. 그렇다면 앞서 V3의 우수한 성능은 “인터넷상의 정보에 의존, ‘멘사 노르웨이’ 테스트에서 ‘부정행위’를 했을 가능성이 크다”는 것이다.

반면에 ‘추론"에 최적화된 R1은 오프라인 전용 테스트에서 약 90점이라는 매우 높은 점수를 받았다. 단, 유료 구독의 오픈AI 모델보다는 못했다.
특히 딥시크의 추론 모델은 기대 이하였다. 즉 IQ 문제 중 “공통 각도를 공유하는 패턴”을 넘어서는 논리는 설명하지도 못했다. 물론 오픈AI의 유료 구독 버전인 챗GPT-o1-pro의 경우도 이 문제에서 거의 실패하고 잘못된 논리를 사용했다. 그러나 논리를 다시 한 번 확인한 후엔 틀린 이유를 깨닫고, 올바른 답을 제시했다.
또 오픈AI의 o1-프리뷰도 문제를 정확히 파악했다. 즉 실패한 패턴을 먼저 시도하지 않고도 답을 잘 찾아냈다. 특히 “오픈AI의 유료 모델 지능은 정말 인상적”이라고 했다. 즉 오픈AI o1 모델은 “평균적인 인간만큼 추상적 사고에 능숙하다”는 것이다.
그러나 딥시크는 온·오프라인 문제 모두에서 오픈AI 유료 모델에 밀렸다. 그럼에도 딥시크는 이 외의 다른 모든 모델과는 동등하거나 한 수 위로 나타난 점 역시 “매우 인상적”이란 평가다.
사용자 만족도, 챗GPT-o1-프리뷰 앞질러
또 챗봇 아레나(Arena)에서도 나란히 두 가지 다른 답변을 얻을 수 있었다. 이는 사용자 만족도 점수를 기준으로 한 것이며, 모델 지능이 IQ 성능과 완벽하게 상관관계가 없음을 알 수 있다. 구체적으로 보면 두 개의 제미니 모델과 챗GPT-4o(제한된 사용 횟수까지 무료)는 사용자 만족도에서 딥시크 R1을 약간 앞질렀다.
하지만 딥시크 R1은 IQ 성능에서 뚜렷한 우위를 점하고 있는 챗GPT-o1-프리뷰를 사용자 만족도에선 약간 앞질렀다.
물론 사용자 만족도는 인간이 평가를 한다는 점에서 좀 다르다. 현실 세계에서는 답변 만족도가 IQ와 완벽하게 일치하지 않는 경우도 흔히 있기 마련이다. 마치 “IQ가 110인 고등학교 교장은 IQ가 140인 물리학 교수보다 훨씬 더 높은 평가를 받을 가능성이 있는 것과 같다”는 얘기다.
이런 점을 보면, AI 지능과 사용자 평가 사이에는 여전히 상관관계가 있지만, 완벽하진 않단 결과다. 이에 대해 맥시멈 트루스는 “AI가 새로운 약물을 개발하거나 희소성 없는 사회를 만들거나 ‘특이점’에 도달하려면 고도의 원시 지능(IQ)이 중요하다”면서 그러나 “자동차를 점프 스타트하려면 어떻게 하나?와 같은 보편적이고 평범한 질문에는 IQ 100과 인터넷 데이터베이스만 있으면 된다”고 비유했다. 즉, IQ테스트에선 챗GPT o1 등에 좀 밀리더라도 사용자 만족도에선 딥시크가 더 나은 이유를 설명한 셈이다.