대용량 집적 메모리 처리, 신속한 대규모 연산 한꺼번에 수행
아직 세계 어디서도 개발 못해, 삼성전자 ‘HBM-PIM 통합’은 완성
“AI반도체 기반, 3자 통합 SW기술 개발자가 ‘최종 승자'”

[애플경제 전윤미 기자] 거대한 LLM 등 인공신경망 학습을 위해선 대규모 메모리를 저장, 연산처리를 위한 NPU와 HBM(고집적 적층식 메모리칩)-PIM(연산처리 메모리칩) 하드웨어 개발이 중요하다. 그러나 궁극엔 인공신경망 학습, 추론 연산을 가속하기 위한 연산 하드웨어인 NPU를 포함한 3자, 즉 ‘NPU-HBM-PIM 통합 시스템’이 조속히 개발되어야 한다는 목소리가 높다.
그러나 아직 국내외를 막론하고 이런 수준의 기술엔 못미치고 있다는 지적이다. 그래서 “NPU-HBM-PIM 통합 시스템 기술이야말로 차세대 AI기술 승부의 관건”이란 얘기도 나오고 있다.
HBM-PIM-NPU 통합 SW, ‘과연 누가 먼저 개발?’
이영민 한국전자통신연구원 선임연구원도 최근 연구 보고서에서 “국내외 기업 및 기관에서는 NPU, HBM, PIM 하드웨어 개발과, 이를 지원하기 위한 소프트웨어 플랫폼 개발을 독자적으로 수행하고 있지만, 이를 통합한 HBM-PIM-NPU 시스템을 지원하고 최적화할 수 있는 기술은 아직 어디에도 없다”고 단언했다.
그는 일단 “인공신경망 학습을 위해서는 다수의 하드웨어에서 효율적으로 연산하기 위한 병렬, 분산 처리 기술이 필수적으로 요구된다.”면서도 이같이 통합된 AI반도체 기반 SW기술의 중요성을 강조했다.
이같은 전문가들의 지적처럼, AI반도체 SW기술의 핵심적인 경쟁 포인트는 HBM-PIM-NPU 통합 시스템 지원을 위한 소프트웨어 플랫폼 기술을 누가 먼저 개발할 것인가 하는 것이다. 또 이를 고려한 병렬, 분산 지원 시스템 기술 개발도 중요한 과제로 꼽힌다.
이에 따르면 ‘HBM-PIM-NPU 통합 시스템’ 모델은 연산처리장치를 아예 메모리 셀 내부나 그 근처에 배치하는 것이다. 이를 통해 대용량의 데이터를 처리할 때 메모리 처리 용량을 늘리고 시간을 줄이는 등 ‘대역폭의 장점’을 지닌 기존 HBM-PIM 통합 모델과, 신경망 처리가 가능한 디지털 연산장치인 NPU를 다시 통합한 모델이다.
지금은 각국이 모두 개별적인 하드웨어를 위한 소프트웨어 플랫폼 개발과 활용에 몰두하고 있다. 그러나 향후 개발이 예상되는 ‘HBM-PIM-NPU 통합 시스템’ SW플랫폼은 이와는 비교가 안 될 만큼 획기적인 장점이 기대되고 있다.
메모리 집약 구간에서는 ‘HBM-PIM’ 하드웨어가 메모리 용량 문제, 즉 대역폭 문제를 해결하고, 복잡한 연산이 집중되는 구간에서는 NPU가 동시에 연산을 가속하는 것이다. 각각의 하드웨어가 지닌 장점을 병렬적으로 수행함으로써 그 효율을 극대화하고, 최적의 작동을 가능하게 하는 것이다.
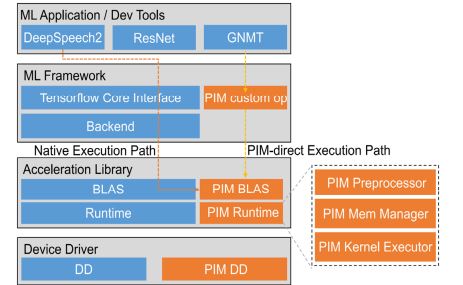
“기존 병렬․분산 SW, HBM-PIM 특성 반영못해”
앞서 이 선임연구원은 “이에 비해 기존의 병렬, 분산 처리 지원 소프트웨어 플랫폼은 HBM-PIM 하드웨어의 특성을 반영하지 못하는 아쉬움이 있다”면서 “HBM-PIM 메모리 대역폭을 고려한 메모리 계층적 최적화 기술(HBM-PIM-NPU 통합 시스템) 개발이 절실히 필요하다”고 강조하기도 했다.
이는 여러 전문가들도 공감하는 대목이다. 최근 한국컴퓨팅산업협회(KCIA)가 주최한 ‘PIM 지능형 반도체 기술 세미나’에서 최규현 한국전자기술연구원(KETI) 선임연구원은 이와 비슷한 내용의 ‘PIM 반도체 기술 동향’을 발표했다.
그는 “PIM이 메인 메모리로 활용돼야 하며, LLM 가속을 위해 NPU와 PIM의 통합 시스템 형태의 솔루션이 필요하다”고 밝혔다. 사실상 HBM-PIM의 통합에 더해 NPU와의 3자 통합 시스템을 염두에 둔 주문이다.
최 연구원은 “LLM은 요약 등을 위해 고사양의 컴퓨팅이 요구되고, 생성 기능을 위해선 높은 대역폭이 필요해 단일 디바이스(가속기)가 이를 동시에 만족시키기 어렵다”며 이같은 통합의 필요성을 강조했다.
그는 특히 “GPU는 높은 컴퓨팅 요구량을 만족하는 반면, 메모리 대역폭 측면에서 효율적인 동작이라고 보기 어렵다”고 한계를 지적하며, “NPU도 동일한 문제가 발생할 수 있으므로, HBM 활용이 필요하다”고 함으로써 사실상 ‘HBM-PIM-NPU 통합 시스템’과 같은 맥락의 기술 개발에 방점을 찍었다.
최 연구원은 또 다시 “PIM은 메모리 내부 대역폭 활용으로 인해 대역폭 요구량은 만족하지만, 많은 연산기를 삽입하는 것이 불가능하므로, 요약 등에 필요한 높은 컴퓨팅 요구량을 충족시키기 어렵다”며 “NPU와 PIM 장점만을 취사선택한 솔루션이 필요하다”고 강조했다.
특히 그는 PIM의 활용 형태로 △가속기 △가속기 메모리 △메인 메모리 3가지 플랫폼을 꼽으면서, 그 중 NPU가 함께 설계된 메인 프로세서(CPU) 내부에 PIM을 함께 탑재하는 방식을 제안했다. 이를 통해 △데이터 전송 오버헤드를 해결하고, △요약과 생성 두 가지를 최적으로 가속할 수 있다는 설명이다.
그에 따르면 물론 이를 위한 PIM 하드웨어와 SW 제작에 어려움이 따를 수 있다. 이에 “PIM 전용 컴파일러와 딥러닝 프레임 워크 상에서 구동되는 라이브러리를 지원함으로써 문제를 해결할 수 있을 것”이라고 제안했다.

국내외 연구소, 기업 등 개발에 ‘박차’
한편 현재도 NPU는 인공신경망 학습과 추론, 연산을 가속하기 위한 연산 하드웨어로서 국내외의 다양한 기업과 연구소에서 개발하고 있다. 또 신경망 거대화로 인한 대규모 연산의 필요성이 증가, 연산 하드웨어와 메모리 하드웨어 간의 메모리 대역폭에 대한 요구사항 또한 크게 증가하고 있다.
이에 메모리 대역폭 성능을 높이기 위한 고대역폭 메모리(HBM)의 경우 삼성전자와 SK하이닉스에서 주도적으로 개발하고 있다. HBM과 함께 개발되고 있는 PIM 역시 높은 메모리 대역폭을 해소하기 위한 기술이다. 즉, HBM-PIM 통합을 통해 신경망 처리가 가능한 디지털 연산기들을 메모리 셀 내부 또는 근처에 배치, 메모리 하드웨어와 연산 하드웨어 간의 데이터 전송량을 줄일 수 있게 된 것이다.
최근 삼성전자가 이 분야에서 가장 앞서가고 있다. 삼성전자는 HBM과 PIM을 통합한 형태의 반도체(HBM-PIMs)를 통합한 AI 가속 솔루션을 선보이고 있다. 또 최근엔 업계 최초로 36GB(기가바이트) HBM3E(5세대 HBM) 12H(High, 12단 적층) D램 개발에 성공하고 고용량 HBM 시장 선점에 나섰다.
그러나 아직은 국내외 어떤 기업도 ‘HBM-PIM-NPU 통합 시스템’ SW플랫폼 개발에 이르진 못하고 있다. 이런 현실에서 “이를 가장 먼저 개발할 경우, AI반도체 기반 SW 기술의 최종 승자가 될 것”이란 전망도 나오고 있다.