정부․대기업․중소기업 구축 역량별 학습 ‘4가지 유형’ 구축 움직임
제1 유형, 1천억개 이상 패러미터 만큼 한글 집중 학습, 정부․대기업 구축
“‘지도형 미세조정’ 데이터셋 구축, DPO로 기능 증강”, GPT 3.5와 맞먹어

[애플경제 전윤미 기자] 생성AI 기술 축적을 위한 한글 기반의 한국형 초대형 언어모델(LLM)의 구축이 절실히 필요하다는 목소리가 높다. 현재 국내에선 한글을 집중적으로 학습시킨 언어 모델이 대부분 13
13B(매개변수 130억개) 이하여서 한계가 있다는 지적이다. 그런 가운데 국내에선 최근 정부와 공공 연구기관 주도로 1천억개(100B) 이상의 패러미터(매개변수)를 지닌 ‘한국형 LLM’ 구축 움직임이 본격화되고 있다.
또 정부와 공공기관, 대기업, 중소기업 등 수요에 따라 적절히 사용할 수 있는 4개 유형별로 한국형 LLM을 구축해야 한다는 주문도 구체화되고 있다.
한국지능정보사회진흥원 구축 주도 예정
이를 주도할 것으로 알려진 한국지능정보사회진흥원(NIA)은 ‘IT&Future Strategy’ 보고서를 통해 이미 그 구체적 내용을 공개, 눈길을 끌었다.
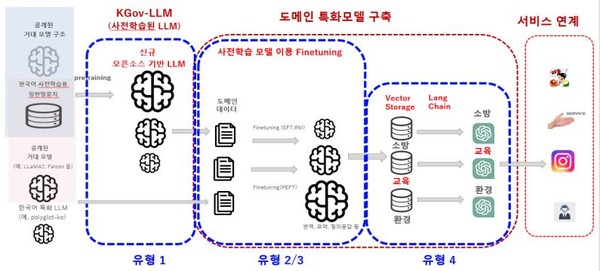
이에 따르면 우선 제1유형으로 100B개의 한글이 집중적으로 학습된 이상적인 규모의 LLM이 구축되어 공개된다. 이는 정부와 대기업이 구현하고, 불특정 다수가 사용할 수 있다. 두 번째는 LLM을 미세조정하고, 양자화한 것이다. 이는 도메인 데이터를 양자화 내지 미세조정한 것으로 대규모 인프라가 필요하다. 역시 정부, 대기업이 구현하고 다수가 사용할 수 있다.
또 제3 유형은 중소기업이나 개인이 구현할 수 있는 것이다. LLM을 패러미터 효율적으로
미세조정하고, 도메인 데이터를 미세조정한 것이며, 적은 수의 GPU가 필요하다. 제4 유형 역시 중소기업이나 개인이 구축할 수 있으며, sLLM에 적합한 RAG(Retrieval Augmented Generation, 검색증강생성)에 의한 것으로 별도 학습이 필요없다. 도메인과 실시간 프롬프트 데이터 기반으로 학습이 필요없고, 적은 수의 GPU만 있으면 된다.
제1 유형 LLM, A100 80GB GPU 1천~5천개 필요
그 중 제1유형은 1천억개(100B)의 매개변수, 즉 그 만큼의 한글이 집중적으로 학습된 LLM이다. sLLM의 경우 A100 80GB GPU가 126~500개 정도면 되지만, LLM은 A100 80GB GPU 1,000~5,000개가 필요하다. LLM은 개인이나 중소기업이 학습 추론을 위한 GPU를 확보하는게 매우 어렵다.
즉 “다양한 분야의 산학연 연계를 통해 다양한 분야에서 말뭉치가 수집되어야 하고, 학습을 위해선 수천대의 GPU를 병렬로 학습해야 한다”는 것이다.
지능정보사회진흥원에 따르면 한글 기반 100B LLM은 향후 GPT 3.5와 비슷한 성능이 될 것이란 기대다.
이를 위해선 패러미터 수를 더욱 늘리고, 충분한 학습데이터로 모델 학습을 가속화해야 한다는 주문이다. 또 “180B(1천800억개)의 패러미터를 갖춘 모델을 개발하고, 친칠라 법칙에 따라 2T 모델 규모의 토큰으로 한글을 학습시키는 것이 필요하다”는 것이다.
이를 위해 ‘지도형 미세조정’(SFT, Supervised Fine Tuning)으로 데이터셋을 생성해야 한다. 1천800억개 패러미터 규모의 LLM 모델을 2T 규모의 한글 토큰으로 학습시켜 기본 LLM을 생성한 후 사용자의 지시에 응답할 수 있도록 RLHF(Reinforcement Learning from Human Feedback) 학습을 수행, 지시응답형(Instruction following) LLM을 생성토록 한다.
“장차 1800억개 패러미터 LLM, 2T 한글 토큰 학습”
또 SFT 데이터셋에 보다 다양한 임무를 추가하면 기능을 증강시킬 수 있다. 특히 알고리즘 기반의 강화학습을 대신하는 DPO(Direct Preference Optimization)기법이 주목받고 있다.
이는 LLM을 지시응답형(Instruction following)으로 변경하기 위해 오픈AI가 써먹었던 학습방법 중 2단계인 ‘보상모델 생성 단계’에 이어 3단계, 즉 PPO(Proximal Policy Optimization)알고리즘 기반 강화학습을 대신하는 것이다. 그 결과 DPO는 요약 및 대화의 응답 품질이 RLHF보다 성능이 뛰어나다는 평가를 받고 있다.
RLHF와 DPO를 비교해보면 이를 알 수 있다. RLHF는 인간의 피드백을 이용하여 학습한 것이다. 즉, 상황에 맞는 높은 품질의 텍스트 생성 모델로서, 출력을 개선해 일관성있고 상황에 적절하게 만든다.
이는 일단 인간의 가치와 선호도를 이해한다. 인간의 선호도에 맞춰 조정하여 유해하거나 바람직하지 않은 결과를 줄여준다. 또 모델이 특정 작업 및 영역에 적응, 다양성을 높여준다. 챗봇이나 가상 도우미, 콘텐츠 생성기와 같은 특정 애플리케이션에 맞게 조정할 수도 있다.
데이터셋 구축, ‘RLHF보단 DPO가 단순하고 효율적’
RLHF의 프로세스를 보면 인간 평가자가 LLM과 상호작용, 순위 형태로 피드백을 제공한다. 또 수집된 피드백을 활용, 보상 모델을 구축한다. 강화학습 알고리즘을 사용, 미세조정을 수행하는 등의 단계를 반복한다.
이에 비해 DPO는 인간의 ‘선호 쌍’ 데이터셋을 생성한다. 각 쌍은 (프롬프트, 선호대답),
(프롬프트, 비선호대답)으로 LLM을 미세조정하여 ‘선호대답’을 생성할 가능성을 최대화하고 ‘비선호대답’을 생성할 가능성을 최소화한다.
DPO는 또 단순성이 특징이다. 즉 RLHF에 비해 구현과 학습이 간단하고, 보상모델을 생성할 필요가 없다. 복잡하게 반복할 필요도 없다.
효율성 측면, 즉 계산측면에서 RLHF보다 훨씬 적은 리소스면 충분하다. 또 사용자가 기본 설정을 직접 학습함으로써 모델 동작을 정확하게 제어할 수 있다.
프로세스 측면에서도 DPO는 선호도 기반 학습, 즉 보상모델 없이 사용자 선호도에서 직접 학습한다. 또 계산 측면에서 경량 학습 프로세스를 단순화해 효율적으로 접근할 수 있게 한다.
이같은 유형1 외에도 한국지능정보사회진흥원은 대기업과 중소기업별로 역량에 맞게 구축할 수 있는 유형2, 유형3, 유형4를 제시하고 있어 주목을 끈다.
<2-②에 계속>