무작위 단어 추출 예측 ‘인코더’ 대신, ‘디코더’로 다음 단어 의미․맥락 파악
초거대 언어모델, BERT, XLM에서 PaLM, 람다, GPT-4로 진화

[애플경제 전윤미 기자] 오늘날 생성AI는 초대형 언어모델(LLM, Large Language Mode)에 기반을 두고 있다. 새삼스럽긴 하지만 그 작동원리는 어떻게 될까. 이는 AI 내지 초거대 생성AI를 이해하기 위해서도 알아둬야 할 대목이다.
애초 언어 모델(Language Model: LM)이란 인간의 언어를 이해하고 자연어와 관련된 다양한 임무를 처리할 수 있도록 학습된 인공지능 모델이다. 수학적인 의미의 언어 모델은 “주어진 단어 순열(즉, 문장)에 대해 확률을 부여하는 모델”을 의미한다. 이 확률은 주어진 단어 순열이 얼마나 그럴듯한지(타당하거나 정확한지)를 나타낸다.
이처럼 모든 문장에 대해 확률 값을 매길 수 있다면 문장마다 한 단어를 처리한 후 다음 단어로는 가장 적합한 단어가 무엇인지를 파악할 수 있다. 이런 식으로 하다보면, 거의 무제한의 글을 생성하는 등 다양한 태스크를 수행할 수 있다.
KB경영연구소나 정보통신기획평가원, 한국전자통신연구원 등 각종 연구기관의 전문가들은 특히 “초거대 언어 모델(LLM)은 수많은 파라미터를 가진 언어 모델”임에 주목하고 있다.
심층학습 아키텍처 발명으로 대규모 파라미터 보유
고기혁_KAIST 사이버보안연구센터 팀장은 “전통적인 의미의 언어 모델은 각 단어 간의 통계적 빈도수를 학습하는 수학적인 확률 모델로 정의되었다”면서 “그러나 이는 그 매개변수(파라미터)의 규모가 제한되었으나, 이러한 한계를 극복하고 다수의 파라미터를 보유하는 동시에 이들을 효율적으로 학습할 수 있는 심층학습 아키텍처가 발명되면서 LLM이 가능해졌다.”고 설명했다.
이로 인해 결국 거대한 규모를 갖춘 초거대 언어모델로 오늘날의 생성AI의 기반이 된 것이다.
여기서 ‘트랜스포머’ 개념이 실현된다. 즉, 초거대 언어 모델 구조의 기틀을 마련한 트랜스포머 모델이 등장한 것이다. 이 역시 등장 초기엔 약 5,000만 개의 파라미터를 보유했다. 그러나 초거대 언어 모델로 발전하면서, 천문학적 숫자의 파라미터로 폭증했다.
구글의 팜(PaLM)이 약 5,400억 개, GPT-4가 약 1조 7,000억 개(추정)의 파라미터를 보유하는 등 그 규모가 기하급수적으로 증가해 왔다. 실제로 2020년 이전의 언어 모델들이 10억 개 안팎의 파라미터를 보유한 반면, 2020년 6월 1,750억 파라미터를 지닌 GPT-3의 등장 이후엔 이처럼 초거대 규모의 모델이 가능해진 것이다.
오늘날 초거대 언어 모델은 ‘트랜스포머’로 불리는 모델을 바탕으로 하고 있다.
앞서 고 팀장에 의하면 트랜스포머는 문장 속 단어들의 관계를 추적해 맥락과 의미를 기록(학습)하는 신경망 구조를 띠고 있다. 마치 사람이 글을 읽으면서 그 의미와 전체 구성을 파악하는 것과도 유사하다.
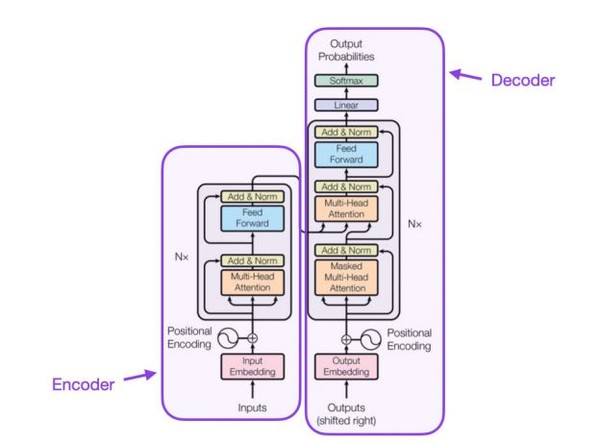
이는 이때 입력되는 문장 순열을 임베딩 벡터로 인코딩하는 인코더(encoder)와, 인코딩된 벡터를 사용하여 여러 연산을 통해 출력 확률을 계산하는 디코더(decoder)로 구성된다.
사전적 의미로 인코더는 ‘지털 전자회로에서 어떤 부호계열의 신호를 다른 부호계열의 신호로 바꾸는 변환기’로 풀이된다. 디코더는 ‘신호를 디지털 부호로 코드화해서 기억하거나 전송할 때 코드화된 신호를 원래 형태로 되돌리는 회로·유니트.’ 정도로 해석된다.
트랜스포머, ‘셀프 어텐션’으로 단어 관계성 학습
“트랜스포머 모델은 이처럼 벡터로 인코딩 처리된 문장을 구성하는 단어들 간의 관계성을 ‘셀프 어텐션’이라는 메커니즘을 사용하여 학습한다. 추론 단계에서는 이러한 관계성을 바탕으로 주어진 문장 배열이 자연스러운지를 파악하는 등의 태스크를 수행한다.
‘셀프 어텐션’에 기반한 모델은 병렬적인 데이터 처리 및 학습을 가능하게 한다. “이를 통해 기존에 순차적인 학습이 필요했던 순환 신경망(Recurrent Neural Network: RNN) 방식에 비해 다수의 데이터 학습에 효과적”이란게 전문가들의 평가다.
이같은 트랜스포머를 기반으로 현재 다양한 구조의 언어 모델들이 개발되고 있다. 이들 초거대 모델은 트랜스포머의 각 구성 요소인 인코더와 디코더를 연속하여 적층한 구조로 보면된다.
그 적층 구조는 크게 세 종류로 나누는게 일반적이다. 전문가들은 “크게는 ‘인코더 오니’(Encoder –only), ‘디코더 오니’(Decoder-only), 그리고 ‘인코더-디코더’(Encoder-Decoder)로 나눈다”는 설명이다.
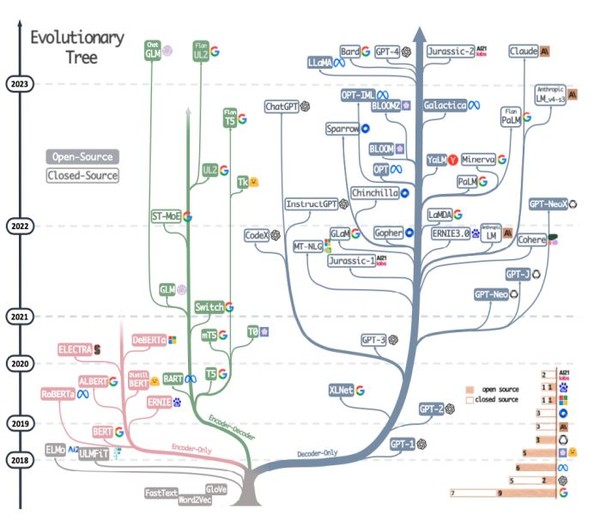
‘인코더 오니’는 트랜스포머의 인코더만을, ‘디코더 오니’는 디코더만을 다수 쌓은 구조를 의미한다. ‘인코더-디코더’는 인코더와 디코더를 모두 사용한 구조다. 2023년 4월까지 공개된 초거대 언어 모델은 그 구조에 따라 수많은 계통수(evolutionary tree)로 확산되어 왔다. 매개변수와 적층 구조에 따라 마치 나뭇가지가 자라듯, 수많은 종류의 LLM으로 발전되어 온 것이다.
지금까지 등장한 언어 모델들을 보면, 그 구조에 따라 모델이 사용되는 학습 기법 또한 다르다.
구글 BERT는 대표적인 ‘인코더 오니’ 모델이다. BERT는 ‘Bidirectional Encoder Representations from Transformers’의 줄임말이다.
이는 ‘인코더 오니’ 모델로서, 입력 문장 가운데 아무 문장이나 무작위로 마스크(masked)한 뒤, 마스크된 단어를 예측하여 학습하는 마스크 언어 모델 학습 기법에 의한 것이다. “이같은 학습 방식은 초기 언어 모델의 발전을 이끌었다.”는 것이다.
GPT 등장으로 ‘디코더 오니’가 대세
이에 반해 ‘디코더 오니’ 모델은 부분적으로 주어진 문장에서 다음 단어를 예측하는 학습 기법을 사용한 것이다.
카이스트 고 팀장은 “대표적으로 초거대 언어 모델 크기 경쟁의 신호탄을 쏘아올린 GPT(Generative Pre-trained Transformers)모델이 그것”이라며 “오늘날 주로 개발되는 LLM은 대부분 GPT의 ‘디코더 오니’ 구조를 띠고 있다”고 설명했다.
다시 말해 ‘인코더-디코더’ 및 ‘인코더 오니’ 스타일의 경우 마스크드(masked) 언어모델로 학습한 것이다. 모델 타입 자체가 생성형이 아닌, 분류형(discriminative)이다. 또 사전학습 태스크는 마스크된 단어를 예측하는 것이다. 버트(BERT), RoBERTa, XLM, DistilBERT, Xlnet, ELECTRA, T5, AlexaTM 등의 모델이 이에 해당한다.
이에 비해 ‘디코더 오니’는 GPT가 대표적이다. 이는 자기 회귀(autoregressive)학습형 언어모델이다. 모델 타입은 생성형(generative)이며, 사전학습 태스크를 통해 다음 단어를 예측한다. GPT-3를 비롯해, OPT. PaLM, BLOOM, MT-NLG, Gopher, LaMDA, LLaMA, GPT-4 등이 그런 종류다.