초거대 AI의 광폭 고속도로? 지연없이 대용량 데이터 연산, 전송
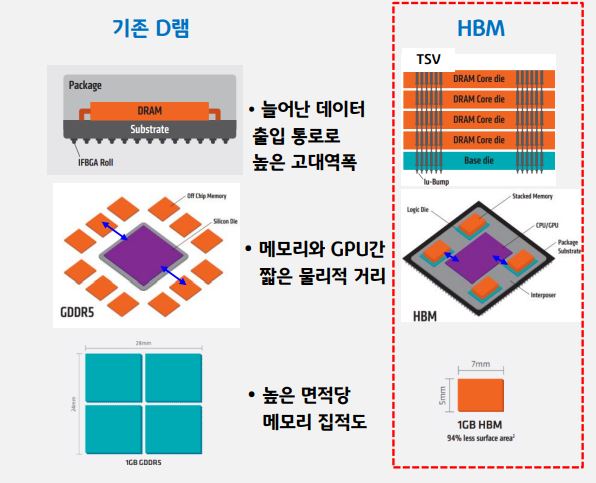
수직으로 쌓은 D램 관통하는 다수의 데이터 입․출입 통로 TSV 확보
전송 속도․용량 크게 높아져, “기술적 어려움, 고비용 등 해결과제”

[애플경제 전윤미 기자] 초대형 생성AI가 등장하면서 특히 고성능 연산능력이 중요해지고 있다. CPU와 GPU, 메모리로 이뤄진 폰 노이만 구조에선 대용량 데이터 전송이 지연될 수 밖에 없다. 이에 병목 현상을 해소하고 빠른 연산이 가능한 HBM((High Bandwidth Memory, 고대역폭메모리)가 다시 주목을 받고 있다.
높은 대역폭, 다량의 데이터 신속 처리와 이동
이는 높은 대역폭으로 한꺼번에 많은 양의 데이터를 이동시키고, 빠르게 처리할 수 있게 한다.
연구기관과 전문가들에 따라 약간의 개념 차이는 있다. 그러나 IT지식포럼 ‘ITFIND’, 정보통신기획평가원, 전자통신연구원 등은 “D램을 실리콘관통전극(TSV) 기술을 적용해 집적회로(다이)를 적층시키는 방식”으로 정의하며, “기존 D램보다 더 많은 데이터 전송 통로(I/O)를 확보해 한번에 많은 양의 데이터를 전송할 수 있다”고 강조했다.
이 밖에 KB금융경영연구소는 “HBM은 여러 개의 D램을 수직으로 쌓은 뒤, 여러 곳에 구멍을 뚫어서 연결하는 TSV(Through Silicon Via, 실리콘 관통 전극) 배선이 데이터 입출입 통로 역할을 한다”고 정의했다.
이에 기존 D램보다 대폭 늘어난 데이터 입출입 통로가 생기고, 데이터 전송 능력이 높아진다. 또 데이터 전송 거리도 축소된다. 즉, GPU 등의 연산처리장치와 물리적인 거리가 가까워지면서 효율적인 데이터 전송이 가능하다. 또 집적도 역시 크게 높아진다. “D램을 수직으로 연결해 기존 D램보다 면적당 메모리 집적도가 매우 높고, 데이터 처리 속도가 향상된다”는 설명이다. 그렇다보니 가격은 비쌀 수 밖에 없다.
이들 전문가 집단의 의견을 종합하면, 한마디로 HBM은 기존 메모리보다 가격이 높은 대신에 고성능 컴퓨팅(HPC)을 발전시킬 높은 잠재력을 지니고 있다. 그래서 산업계에선 고성능·고부가가치 메모리 시장의 패러다임을 바꿀 것으로 내다보며, 개발 경쟁 또한 치열하다.

현재 HBM 4세대 개발, 날로 성능 향상
현재 HBM 시장의 패권은 삼성전자, SK하이닉스로 대표되는 국내 기업들이 주도하고 있다. 특히 HBM 3세대에 이어, 최신 HBM4 등에선 SK하이닉스가 시장을 선점하고 있다.
그 동안 HBM1, HBM2는 고성능 컴퓨팅(HPC)이나 GPU 기반 딥러닝(심층학습) 기기 등에 데이터의 고속 처리를 위해 주로 도입되었다. 그러나 HBM은 세대가 바뀔 때마다 처리 속도가 향상되면서 인공지능용 그래픽처리장치에 탑재되었다. 대역폭이 높을수록 한번에 실어 나를 수 있는 데이터량이 증가하고 데이터 처리 속도도 빨라진다.
SK하이닉스와 시스템반도체 설계사인 AMD가 함께 만든 HBM 1세대 제품은 핀(Pin)당 1Gbps였다. 그러나 2022년 출시한 4세대 HBM3은 6.4Gbps로 높아졌는데, 이는 초당 819GB(기가바이트)의 데이터를 처리할 수 있는 성능이다.
HBM3의 경우 종전 GPU와는 달리, 엄청나게 많은 핀(Pin)을 탑재, 획기적으로 속도와 성능을 높였다. 본래 GPU에는 GDDR6(Graphics Double Data Rate 6)라는 고성능 D램이 사용되어 왔다. 그러나 이는 데이터 입출력 통로인 핀의 개수가 32개에 그쳐, 인공지능 연산에서는 데이터 이동 병목 현상이 발생하곤 했다.
그래서 가장 최신 세대인 HBM3은 1024개의 핀을 탑재, GDDR6의 12.8배나 높은 대역폭을 확보하면서 훨씬 빠르게 데이터를 처리할 수 있게 된 것이다. 초대형 모델 기반의 AI시장이 확대되면서 이제 HBM은 빠른 연산을 위한 필수적인 메모리로 부상하고 있다.
실제로 챗GPT와 같은 대규모 AI 모델의 경우 메모리 병목현상으로 문장 생성 속도가 지연되기도 한다. 그러나 최신 HBM-PIM 기술을 적용할 경우 기존 HBM이 탑재된 GPU 가속기에 비해 AI 모델의 생성 성능이 약 3.4배나 빨라진 것으로 전해졌다.
성능과 전력 효율 높일 ‘패키지 기술’ 필요
HBM은 일종의 반제품이다. ‘ITFIND’에 따르면 CPU, GPU 등의 로직 칩과 유기적으로 연결돼 동작하는 것이다. 특히 “이론상 칩 하나에 메모리를 더 많이 넣을수록 용량이나 성능은 더 좋아지지만, 그만큼 기술적 어려움도 커져서 HBM 메모리 용량을 늘리려면 아직은 물리적 한계가 존재한다”는 지적이다.
그래서 “이런 물리적 한계를 극복하기 위해 성능과 전력 효율을 극대화할 패키지 기술이 필요하다”는게 ITFIND 연구진의 진단이다.
패키지는 반도체를 전자기기에 맞는 형태로 제작하는 공정이며, 전기 신호가 흐르는 통로를 만들고 외형을 가공해 제품화하는 것이다.
요약하면, HBM은 일단 높은 대역폭 덕분에 데이터 이동 과정의 병목 현상을 해소할 수 있다. 또 D램의 수직 집적으로 인해 공간을 절약할 수 있고, 이로 인해 공간 효율성과 전력 효율성을 기할 수 있다는 게 장점이다.
그러나 기술적, 그리고 공정상의 어려움이 크다. 수율도 낮은 반면 기존 D램에 비해 제조 비용이 많이 든다. 또한 단기적으로 시장 침투율이 낮다는 것도 단점으로 꼽힌다. 이런 문제를 해결해야만 초대형 생성AI 흐름에 맞춰 본격적인 HBM의 시대가 열릴 것이란 전망이다. < (2-②)에 계속>