토픽모델링, 조건부 확률적 언어모델 방식 등으로 연구 현황 ‘키워드’ 분석
항만IoT, 항만안전, 엣지컴퓨팅, 온톨로지, 클라우드 등 서비스 관련 다수

[애플경제 전윤미 기자] 국내에서도 생성AI 기술 개발과 연구가 날로 활성화되고 있다. 그런 가운데 국내에선 생성AI 원천 기술보다는 생성AI를 이용한 콘텐츠나 서비스 분야에 집중되어있는 것으로 나타났다. 이는 전문가에 의해 문서의 자연어 처리 기법 중 하나인 토픽 모델링 방식으로 연구 키워드를 분석한 결과다.
최근 나윤빈 신구대 교수는 “국내 생성AI 연구․개발의 실제 수행주체는 중소기업과 대학, 출연연구소들이 주로 맡아하고 있다”면서 이같이 밝혔다.
그는 최근 정보통신기획평가원을 통해 공개한 ‘국내 생성형 인공지능 연구․개발 현황’ 논문을 통해 이같은 토픽 모델링 방식에 의해 연구 키워드의 빈도를 분석한 결과를 소개했다. 이에 따르면 일단 딥러닝, 빅데이터 등 일반적으로 생성 AI와 연관성이 높은 단어들이 상위권에 나타났다. 그 과정에서 나 교수는 특히 30위권에 들어간 키워드를 강조하고 있다.
연구 키워드 30위권 중심으로 분석
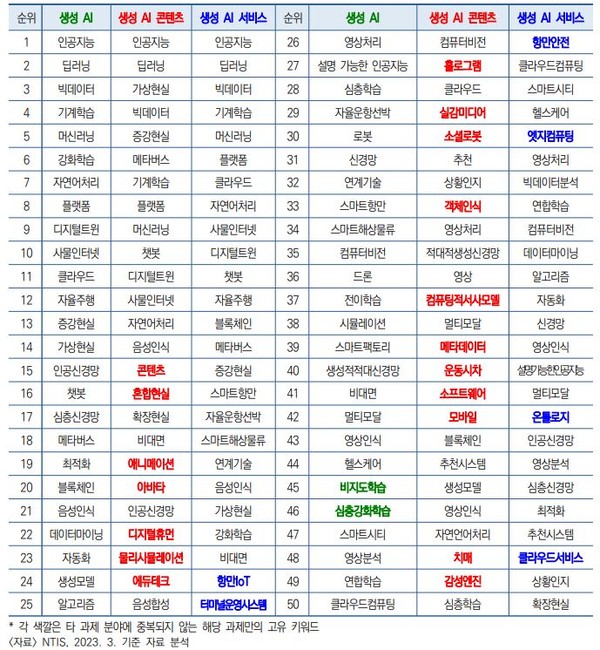
우선 키워드 빈도를 분석한 결과에 따르면 생성AI를 응용한 각 분야의 기술명칭인 디지털트윈, 음성인식, 영상처리, 자율운항선박 등이 30위권에 들었다. 이 외에 생성적 적대신경망(GAN), 스마트항만, 스마트시티, 헬스케어 등의 단어도 50위 내로 나타났다. GAN을 제외하곤 대부분 생성AI 서비스와 관련있는 기술들이다.
그에 따르면 또한 생성 AI(비지도학습), 생성 AI 콘텐츠(혼합현실), 생성 AI 서비스(항만IoT)의 각 분야마다 고유한 키워드가 부분적으로 등장했다. 물론 분야별 상위 키워드를 서로 비교분석한 결과, 여러 단어가 겹치는 것으로 나타나긴 했지만, 고유한 키워드가 존재할 수 밖에 없다는 해석이다.
나 교수의 분석을 좀더 구체적으로 보면, 빈도분석 결과, 인공지능, 딥러닝, 빅데이터, 기계학습, 머신러닝 등이 상위 그룹으로 나타났다.
또 생성AI, 생성AI 콘텐츠, 생성AI 서비스 등 3가지 분야별 주요 키워드의 빈도를 비교, 분석한 대목도 흥미를 끈다.
이 경우 생성 AI에서는 비지도학습, 심층강화학습이 고유한 키워드로 나타났다. 생성 AI 콘텐츠에선 이 보다 훨씬 많은 키워드가 등장했다. 즉, 콘텐츠, 혼합현실, 애니메이션, 아바타, 디지털휴먼, 물리시뮬레이션, 에듀테크, 홀로그램, 실감미디어, 소셜로봇, 객체인식, 컴퓨팅적 서사모델, 메타데이터, 운동시차, 소프트웨어, 모바일, 치매, 감성엔진 등이다.
생성 AI 서비스에서는 항만IoT, 터미널운영시스템, 항만안전, 엣지컴퓨팅, 온톨로지, 클라우드서비스가 주요 키워드로 나타났다. 각기 세 분야별 30위권에 든 키워드는 모두 서로 중복되는 것으로 분석되었다.
‘N-gram’을 통한 키워드 분석도
나 교수는 또 ‘N-gram’을 통한 키워드 분석도 구사했다. 즉, 단어의 연쇄 확률을 조건부 확률로 계산하여, 특정 단어 다음에 등장할 단어를 예측하는 조건부 확률적 언어모델 방식을 적용한 것이다. 이를 통해 생성 AI, 생성 AI 콘텐츠, 생성 AI 서비스 분야의 연관어를 비교했다.
그 결과 인공지능이 가장 많았고, 딥러닝, 빅데이터, 기계학습, 증강현실, 가상현실, 플랫폼 등의 단어가 함께 붙어 있는 경우가 다수였다. 또 생성 AI와 생성AI 서비스 분야의 일부 키워드가 중복되기도 했다.
“세부적으로 보면 ‘생성 AI 콘텐츠’의 경우, ‘생성AI’에 비해 인공지능 외에 가상현실, 증강현실, 메타버스의 키워드가 연관되는 형태로 높은 빈도를 보이고 있다”면서 “이같은 기술들이 콘텐츠 생성과 창작에 집중되었음을 알 수 있다”고 했다. 더욱이 “‘생성 AI 서비스’의 경우는 ‘생성 AI 콘텐츠’보다 더 높은 빈도를 보이고 있는 가운데, 인공지능과 항만 관련 기술 외에 빅데이터, 클라우드 등 서비스 기획 및 유통에서의 연계기술로 집중되었다”고 덧붙였다.
특히 생성 AI 콘텐츠 분야에서 고유 키워드가 가장 많은 것으로 나타났다. 다만 생성 AI와, 이를 응용한 생성 AI 서비스는 마치 ‘동전의 양면’과 같은 성격이어서, 상대적으로 유사하거나 중복된 키워드가 다수 나타났다. 이에 대해 나 교수는 “생성 AI 분야 내에서도 아직까지 국내에선 생성AI나 콘텐츠 연구 개발보다는 서비스 부분에서의 연구 개발이 활성화되어 있음을 의미한다”고 결론지었다.
“생성AI나 콘텐츠 연구보다 서비스 연구 활성화”
한편 나 교수는 이같은 연구 분석을 위해 NTIS(한국과학기술지식정보서비스)에서 수집된 정보를 대상으로 한글 키워드를 사용한 빈도분석과 토픽모델링 등 딥러닝을 이용한 자연어 처리기법을 구사했다.
한 문서에서 특정 단어가 차지하는 가중치를 측정하는 ‘TF-IDF’((Term Frequency-Inverse Document Frequency) 기법, 그리고 또 ‘잠재 디리클레 할당’ 기법, 즉 LDA(Latent Dirichlet Allocation) 토픽 모델링 방식으로 토픽을 산출했다.
특히 국내 생성AI 기술 연구 동향을 분석하기 위해 토픽 모델링 방식을 유용하게 구사했다. 즉, 데이터에서 특정 토픽(주제)을 클러스터 형태로 도출하는 것으로, 대표적 알고리즘인 LDA 방식에 의해 생성AI 연구 과정에서 등장하는 주요 토픽과, 토픽 내 단어 구성, 데이터 내 토픽 분포 등을 파악했다.