전문가들 “코드 개선 아닌, 데이터 개선으로 AI모델 성능 향상해야”
“풍부하고 품질좋은 데이터 수집․가공, 일관되고 정확한 라벨링이 우선”

[애플경제 전윤미 기자] 품질좋은 AI시스템을 위한 데이터 라벨링의 중요성이 날로 강조되고 있다. 시중에선 라벨링 작업을 하는 ‘데이터 라벨러’가 인기 프리랜서 직종으로 부상할 정도다. 이는 AI시스템의 성능을 높이기 위해선 코드의 개선보다는 데이터를 개선하는 것이 더 효율적이란 주장이 설득력을 얻고 있는 것과도 맞물리는 현상이다.
일반인을 포함한 불특정 다수를 대상으로 한 데이터 라벨링 사업을 하고 있는 ㈜크라우드웤스의 박영진 본부장도 그런 전문가의 한 사람이다. 그는 “코드에 초점을 맞추는 대신 신뢰성, 효율성, 체계적인 방식으로 데이터를 개선하기 위한 시스템 기반 엔지니어링 프랙티스를 개발하는 데 주력하는 데이터 중심 접근법으로 이행해야 한다”고 주장하고 있다.
그는 최근공개한 ‘ICT 트랜드’ 보고서를 통해 “실제 AI 시스템은 인공지능 알고리즘인 코드와 데이터로 구성되어 있다”면서 “따라서 AI 시스템의 성능 개선도 코드 중심인지 데이터 중심인지에 따라 나누어 볼 수 있다”며 이같이 밝혔다.
그에 따르면 현재는 대부분의 AI연구자들은 모델 관점에서 AI성능을 개선하는데 주력하고 있다. 즉, 머신러닝 모델에 필요한 특성을 선택, 추출해서, 모델의 복잡성을 줄이고, 이를 통해 불필요한 정보를 제거한다. 또 모델이 핵심적인 특성을 잘 학습할 수 있도록 성능을 개선하거나, 적절한 하이퍼파라미터를 찾아서 튜닝하기도 한다. 때론 여러 개의 머신러닝 모델을 조합하는 ‘앙상블 기법’ 등을 통해 더 나은 성능을 내는 모델을 만드는데 주력하는게 보통이다.
해외 전문가들 ‘데이터 중심 AI시스템’ 주장 많아
그러나 박 본부장은 정보통신기획평가원을 통해 공개한 소논문 형태의 보고서에서 지난 2021년 3월, 스탠포드 대학교 교수 출신의 유명한 인공지능 연구자 앤드류 응(Andrew NG)의 주장을 인용하며, 데이터 중심 AI 시스템의 중요성을 강조했다.
그에 따르면 당시 앤드류 응은 “AI 모델 연구에 집중되어 있는 연구 패턴을 바꿔, 모델 중심이 아닌 데이터 중심으로 발전해 나가야 한다”면서 이른바 ‘데이터 중심 AI(Data centric AI)’를 제시한 바 있다.
이에 따라 최근 국내에서도 코드 아닌 데이터 중심의 AI 성능 연구가 점차 인식되고 있는 추세다.
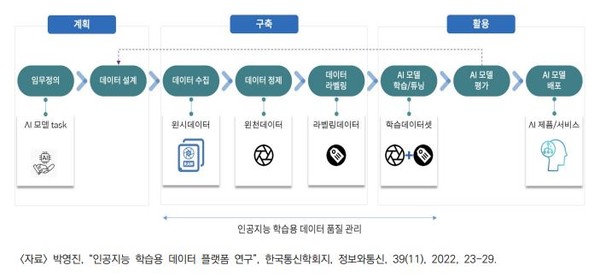
일단 데이터 관점에서 성능을 높이기 위해서는 데이터의 품질을 높이고 수량을 늘려야 한다. 데이터가 많으면 노이즈가 포함되어 있어도 모델 성능에 큰 영향을 미치지 못한다. 그래서 충분하고 양호한 품질의 데이터 라벨링이 중요해지는 이유다. 이미 국내에선 앞서 ㈜크라우드웤스를 비롯해 많은 데이터 라벨링 전문업체들이 경쟁을 벌이고 있다.
이는 풍부한 양질의 데이터로 AI성능을 높일 수 있다는 관점이 설득력을 얻고 있기 때문이다. “그러기 위해선 많은 양의 데이터를 수집하고 수집된 데이터에 일관성 있는 작업과 품질을 유지하여 데이터 라벨링이 이루어져야 한다.”는 얘기다.
“라벨러, 관리자, 작업 품질이 더욱 중요해져”
여기서 데이터 라벨러와 관리자, 작업 프로세스의 품질이 중요해진다. 이를 통해 데이터 라벨링의 정확도, 라벨링의 일관성, 객체 다양성 등 데이터 품질이 보장될 수 있기 때문이다. 현재 국내에선 한국인공지능협회가 주장하는 데이터관리사 1․2급 자격제도가 있다. 데이터 라벨링 업계에선 대체로 1급 자격 정도를 취득한 경우에 라벨링 작업을 맡기는 경우가 대부분이다.
현재 데이터 전처리나 일부 데이터 가공은 대체로 전문가들이 수행하지만, 대부분의 데이터 라벨링은 일반인을 포함해 소정의 교육을 받고 자격을 취득한 데이터 라벨러들에 의한 수작업으로 이뤄진다. 이를 위해 데이터 라벨링 작업에 참여하기 위해 신청을 하면, 별도의 라벨러 교육부터 먼저 받게 된다.
그런 다음 팀이나 그룹에 의한 데이터 라벨링 작업 검수, 데이터 라벨링 작업 성과 분석, 데이터 라벨러 성과 분석 등 복잡하고 다양한 절차로 이어진다. 이 경우 작업 성과에 따라 라벨러들에게 소정의 비용을 지불하는 경우가 대부분이다. 업체에 따라선 “최소 100만~500만운의 월수입이 보장된다”고 안내하기도 한다.