때묻은 AI모델, 부정확, 편견․오류많아, 오염원 예방․차단이 관건
데이터오염, 모델오염, 모델 추출공격, 회피공격 등 오염원 다양

[애플경제 김향자 기자]챗GPT 등 생성AI의 부정확성이나 편견, 오류에 대한 지적도 많다. 그 원인은 여러 가지가 있겠으나, AI학습모델 구축 단계에서 오염되었거나, 잘못된 정보, 데이터가 입력된 경우가 가장 많다. 특히 데이터오염 공격, 모델오염 공격, 모델 추출공격, 회피공격 등의 오염원을 어떻게 사전에 방지하느냐에 따라 AI모델의 품질과 그 정확성이 결정된다.
최근 금융보안원의 ‘AI보안 가이드라인’이나 한국지능정보사회진흥원의 ‘파운데이션 모델 연구 동향’, 정보통신기획평가원의 ‘인공지능 학습용 데이터 구축 연구’ 등 국내 AI연구에 의해서도 그 중요성이 부각되고 있다.
가장 직접적인 ‘데이터 오염’
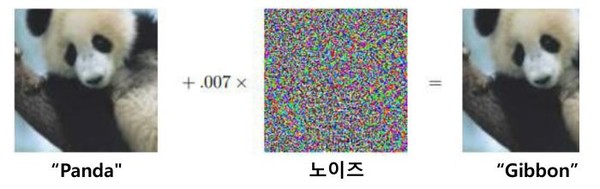
이를 종합해보면 우선 AI학습모델을 오염시키는 가장 직접적 원인은 데이터 오염이다. 즉, 적대적 예제 또는 악의적인 노이즈 등이 삽입되어 오염된 데이터를 AI 모델 학습에 활용, AI시스템의 성능을 저하시키고, 오작동을 유발하게 하는 것이다.
이는 AI 모델 자체를 공격한다는 점에서 대표적인 오염원이다. 이를 방지하기 위해서는 학습에 활용하는 데이터의 오염 여부를 학습 전에 확인하는게 최선이다. 그 중 ‘데이터 백도어 공격’의 경우는 AI 알고리즘 자체가 공격자의 악의적인 데이터를 학습하게 하는 교활하고 지능적인 수법이다.
“이처럼 AI 모델이 오염된 데이터를 학습하면 당연히 모델의 정확도가 저하될 수 밖에 없다”는게 금융보안원의 진단이다.
데이터 오염 공격은 ‘이상치’를 미리 처리함으로써 예방하거나 차단할 수 있다. 이때 임계치를 이상 점수(Outlier Score)로 정하고, 이상 점수 밖에 위치하는 오염된 데이터를 찾는 방법을 많이 쓴다. 또 클러스터링 기법을 활용, 클러스터 밖에 위치하는 오염된 데이터를 찾는 방식도 활용할 수 있다.
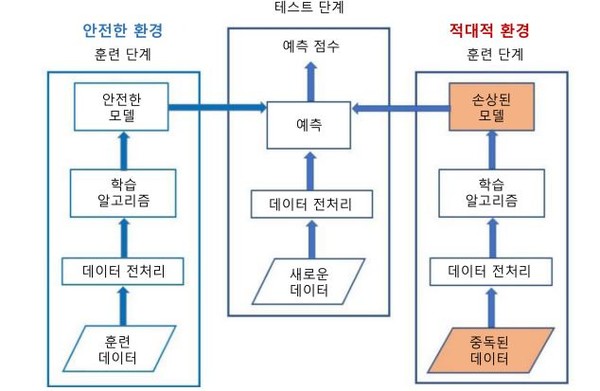
악의적 클라이언트 의한 ‘모델 오염 공격’
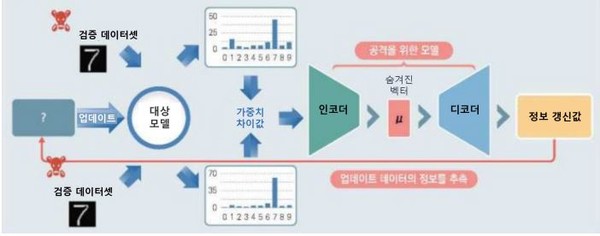
데이터 오염과 함께 가장 흔한 오염 방식은 ‘모델 오염 공격’이다. 이는 연합학습을 할 때 클라이언트로부터 학습되고 생성된 악의적인 모델이 중앙서버의 AI 모델에 틈입, 성능을 떨어뜨리고 오작동을 유발하는 것이다.
이 경우 서버가 각 클라이언트에서 전달되는 모델의 신뢰성이나 오염 여부를 확인하는게 쉽지 않다. 그래서 모델 오염 공격은 탐지하기 어렵다.
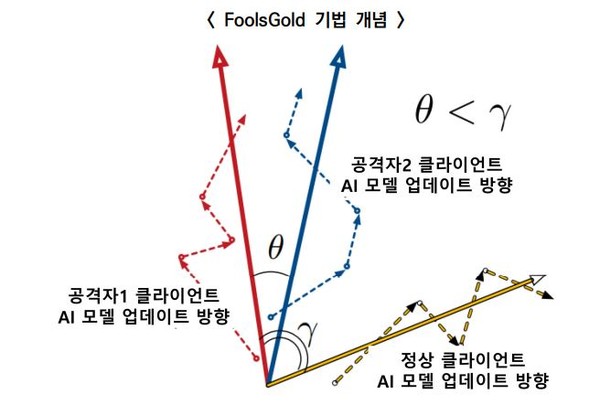
모델오염공격을 예방하기 위해선 특히 ‘FoolsGold 기법’이나, ‘집계 알고리즘 적용’ 등의 방법을 많이 쓴다.
그 중 ‘FoolsGold 기법’은 연합학습을 할때 이를 통해 악성 클라이언트를 판별하고 배제하는 것이다. 즉, 정상 클라이언트와 악성 클라이언트 간 경사도를 비교해서 서로 다른 업데이트 양상을 확인, 악성을 판별하는 기법이다. 이때 경사도는 정상과 악성 클라이언트에 의해 달라진 학습 결과의 변화양상을 말한다.
또 ‘Feature Squeezing’ 기법도 있다. 이는 AI 모델의 예측 결과와 ‘Squeezer 알고리즘’을 적용한 예측결과를 비교함으로써, 적대적 예제를 탐지하는 방식이다. ‘Squeezer 알고리즘’은 기존 입력값의 인코딩을 단순화하고, 평활화 필터 등을 적용하여 특징을 축소하는 것이다.
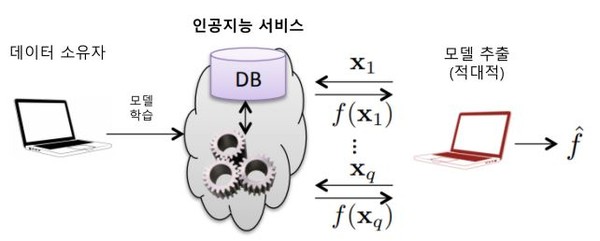
원본AI모델 복제, ‘모델 추출 공격’
모델 추출 공격도 AI모델의 품질을 떨어뜨리는 큰 요인이다. 이는 원본 AI 모델로부터 유사한 모델을 추출하여 복제하는 교활한 공격 수법이다.
즉, 원본 AI 모델에 대한 대량의 쿼리를 통해 입・출력값을 수집하고, 이를 학습하여 원본AI 모델과 유사도가 높은 모델을 복제하는 것이다. 심지어 해외 사례를 보면 불과 몇 분만에 유료 AI 모델을 99% 이상의 닮은꼴인 형태로 복제하기도 했다.
이런 경우는 우선 출력 횟수와 시간을 제한하여 공격자의 입・출력 정보 수집을 어렵게함으로써 예방할 수 있다. 또 비식별 처리 등을 통해 출력값을 변환하면, 입・출력값으로부터 공격자가 유사 모델을 생성하기 어려워져 모델 추출 공격을 예방할 수 있다.
특히 ‘DP-SGD 기법’을 많이 쓴다. 이는 학습 과정에서 이른바 ‘차등 프라이버시 기법’을 적용함으로써, 경사도 등 모델과 관련된 정보 노출을 최소화하는 기법이다.
본래 ‘SGD’는 AI 모델 학습 방식의 대표적인 방법으로, 입력 데이터를 작은 크기로 분할 집합(Mini Batch)하여 학습을 진행하는 것이다. 그런 식으로 진행된 AI 모델 학습은 다시 말해 새로운 데이터을 입력할 때마다 AI 모델 내의 노드 등의 수치가 최적화(Optimize)되는 과정으로 해석된다.
이때 ‘DP-SGD’는 작은 크기로 데이터를 분할집합하는 방식에서 나아가 ‘차등 프라이버시 기법’을 적용하여 학습을 진행하는 방식이다.
즉 분할 집합마다 각 가중치를 구하고 최대 기울기 제한(Clip Gradient)이나, 통계적 기반의 노이즈(Gaussian Noise)를 추가하여 학습을 진행한다. 이런 기법을 쓰게되면 공격자는 출력값을 기반으로 입력값을 유추하기 때문에 모델을 유추하기가 어려워진다.
출력값에서 입력값 유추, ‘모델 인버전 공격’
아예 모델의 출력값으로부터 입력값을 유추하는 모델 인버전 공격도 있다. 즉, 모델 종류, 파라미터 등 알려진 정보를 기반으로 ‘대리 모델’을 만들어 공격하는 것이다. 대리모델은 원본 모델의 예측을 정답으로 삼으며, 지도학습을 통해 학습한 유사모델이다.
이때 공격자는 쿼리를 통한 입・출력값이나, 신뢰 점수(Confidence Score), 즉 신뢰구간에 모집단의 실제 평균값이 포함될 확률을 추측함으로써 학습 데이터를 추측할 수 있다.
모델 인버전 공격 역시 앞서 모델 추출 공격과 마찬가지의 방법을 통해 입・출력값을 보호함으로써 공격을 예방, 차단할 수 있다.
노이즈 추가 적대적 데이터 입력 ‘회피 공격’
이 밖에 잘 알려진 ‘회피 공격’이 있다. 이는 노이즈를 추가한 적대적 데이터를 입력하여, AI 모델이 잘못된 판단을 하도록 유도하는 공격이다. 이를 위해 적대적 예제 학습이나, 경사도 마스킹 등의 방법을 통해서 회피 공격을 예방하고 차단할 수 있다.
이때 사전에 적대적 예제를 생성하여 학습함으로써, 적대적 예제를 통한 회피 공격을 방어할 수 있다. 또 공격자는 데이터를 입력한 경우, AI 모델의 학습 방향 등 변화되는 정도를 기반으로 적대적 예제를 생성할 수 있다.
특히 공격자가 알아내고자 하는 AI 모델의 학습 방향은 데이터 입력 시에 AI 모델의 경사도를 통하여 확인할 수 있다. 그러나 경사도를 공개하지 않거나 마스킹하는 방법, 또는 범주화하는 등의 기법을 통해 모델에 관한 정보를 최대한 은폐할 수 있다.