AI가 동작의 각도, 주변환경 학습, 재현…‘3D 사람 형상 투시 복원술’
포스텍, 서울대, 카이스트 등 연구, “범죄 예방과 검거에 매우 유용”
“CCTV 사각지대, 은폐물 너머 형상도 알아낼 수 있어”

[애플경제 전윤미 기자]책상이나 물체에 가려진 동작이나 신체의 일부는 보이지 않는다. 특히 CCTV에 범죄자 신체의 일부만 찍혀 특정할 수 없는 경우가 많아 검거나 예방에 애를 먹곤 한다. 최근 포스텍(포항공대), 서울대, 카이스트 등에선 신체의 일부가 가려지거나 사각지대에 있는 경우, 보이지 않는 부분을 AI가 추론하여 3D로 재현해내는 기술을 연구, 성과를 내고 있다.
사람․물체 간 위치 관계에 대한 상식 바탕, 복원
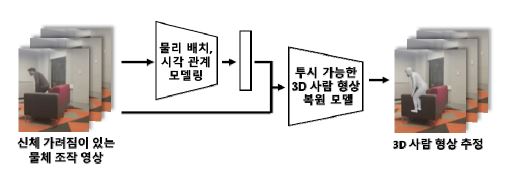
이 기술은 우선 비디오에 찍힌 특정인의 주변 물체를 분석하고, 그 시간과 사람이 서있거나 앉아있는 모습의 시각(각도) 관계 등을 AI에게 학습시킨다. 그런 다음 이를 투시할 수 있는 3D 사람 형상으로 추정, 재현하는 것이다. 만약 이 기술이 보편화될 경우 특히 범죄예방이나 검거에 매우 유용하게 쓰일 것으로 보인다.
특히 최근엔 오태현 포항공대 조교수가 최근 정보통신기획평가원에 게재한 ‘비디오에서의 가려짐을 투시 가능한 3D 사람 형상 복원 기술’ 보고서를 통해 이같은 기술을 상세히 소개하고 있어 주목을 끈다.
그에 따르면 이는 AI가 사람과, 그를 가린 물체 간 위치 관계에 대한 상식을 내재한 ‘비디오 형상 복원 모델’ 연구로 요약할 수 있다. 또한 사람이 신체가 대부분 가려진 상황에서, 시간에 따라 변화하는 주변 물체와, 그 사람이 위치하거나 주변 환경과의 배치관계 등을 분석, 추론하는 모델을 기반으로 한 것이다.
AI가 시각적 ‘상식’을 구현, 전체 형상을 추론
이때 역시 핵심은 AI다. 즉 AI가 비디오 시각(각도) 장면이 시간에 따라 (변화하는) 사람의 (행위나) 일부 정보를 보고 전체를 형상화하고 추론하는 기능을 모사하는 것이 기본이다. 즉, 영상에서의 사람과 물체 간의 시간적, 물리적 시각 관계를 추론하여 시각적 ‘상식’(대상에 대해 가장 가능성이 큰 인식)을 구현하는 것이다. 그렇게 구축한 시각적 ‘상식’을 통해 가려져있는 사람의 일부 신체를 온전한 3차원의 온전한 모습으로 복원하게 된다.
다만 “영상에서 관찰되는 사람의 시각적 정보는 가려짐에 의해 불완전하게 전달되는 경우가 많아 3차원 정보를 복원하기 위해서는 사람과 물체 간의 시간적, 물리적, 시각적 상식에 대한 이해가 필요하다”는 오 교수의 지적이다. 이를 위해 AI가 사전에 다양한 영상으로부터 학습된 ‘상식’을 기반으로 이처럼 신체 일부분의 정보만 주어진 영상으로부터 3차원 정보(사람의 전신(全身))를 추론하는 방법이 현재 연구 중이다.
국내 연구기관들, 신체일부 가려진 ‘메시’ 생성기술 연구
이미 포항공대(포스테크)에선 이와 유사한 다양한 객체의 3차원 ‘메시’를 복원하고 생성하는 기술을 개발했다. 이는 단적으로 말해 사람과 4족 보행 동물의 통합된 3차원 형상 복원 기술 개발이란 설명이다.
즉, 사람과 동물이 가지는 형태학적 상식을 기반으로 통합된 3차원 형상 복원 기술로서, 사람과 개별 동물마다 각기 다른 3차원 형상 추정 데이터를 바탕으로 효율적인 알고리즘을 개발 중이란 소식이다.
이는 시각적 ‘상식’을 기반으로 신체 일부가 가려진 사람 모형인 ‘메시’를 완성시키는 생성 모델이다. 3차원 공간 안에서 사람이 취할 수 있는 ‘단위 행동’에 대한 상식을 기반으로, 자연스러운 사람 3차원의 ‘메시’를 생성하고, 위치를 분석하는 기술로 해석된다.
서울대학교도 비슷한 수준의 기술을 개발했다. 이는 다중(多衆)으로 인해 특정인의 신체 일부가 보이지 않는 경우, 그 부분에 대해 선명한 3D 볼륨 ‘바디’(body)를 생성하는 방법이다. 특히 “2D 스켈레톤 추정이 3D 스켈레톤 추정보다 가려진 부분을 추정하는데 더욱 유리하다는 점을 활용했다”면서 “영상에서 추출된 2D 스켈레톤으로부터 짐작되는 특징적인 벡터를 활용하여 다중 객체 내에서 특정인의 볼륨 바디를 강건하게 생성하는 모델 구조”라는 얘기다.
카이스트 역시 적대적 학습 방법(GAN)을 통해 학습조건으로 주어진 사람의 행동에 대한 스타일을 추출하고, 또 다른 사람의 행동에 적용하기 위해 특정인의 행동에 적합하게 스타일을 변형하는 기술을 개발했다.
美스탠포드대, MS 등도 유사 기술…“아직은 한계 많아” 지적도
해외에서도 이같은 시각 ‘상식’을 이용한 인지 추론과, 영상 이해 연구를 진행하고 있다.
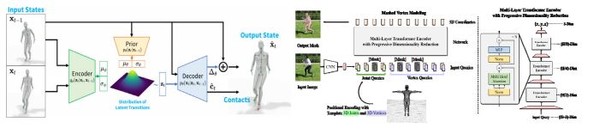
미 스탠포드대의 어도비 연구소가 대표적이다. 이곳은 사람의 3차원 동작과 운동 상태(state)의 확률 분포로 모델링한 점이 특징이다. 영상 속 특정 시점의 프레임에서의 운동 상태를 기반으로 그 직후의 프레임에서의 상태를 추정, 생성하는 것이다.
이를 통해 사람 행동에 대한 사전 상식을 학습할 수 있고, 신체 일부가 가려진다 해도, 이같은 사전 ‘상식’을 기반으로 가려진 부분을 추정, 복원할 수 있다.
마이크로소프트도 이 분야 연구에 매진하고 있다. 일단 2D 이미지에서 사람의 3차원 ‘메시’의 꼭지점 좌표를 직접 추정하여 형상을 복원하는 기술이다. 그 과정에서 트랜스포머를 접목하고 있다. 특히 사람의 관절에 주목, 쿼리(Query) 차원에서의 무작위한 마스킹(masking)을 통해 관절 간 상관관계를 측정할 수 있음을 확인했다. 이를 활용하여 가려짐이 있는 신체에 대해서도 관절 간의 관계를 기반으로 복원할 수 있게 된 것이다.
이런 가려짐 3D복원 기술은 아직은 한계점이 있다는 지적이다. 오 교수는 “현재는 객체의 시간적인 운동 상태만을 고려하는 쪽으로 연구되고 있다”면서 “물리적으로 해석 가능한 객체와 장면 간의 관계성을 내포하는 기술은 부족한 상황”이라고 밝혔다.