단순한 언어모델 벗어나 텍스트․이미지․동영상 등 창작행위
모달리티의 자유로운 변화 ‘크로스모달’ 확산, 단순 텍스트 뛰어넘어
코드나 이미지, 음성, 비디오, 3D 생성, “앞으로도 예측불가”
[애플경제 김향자 기자] 챗GPT 등장으로 초거대 AI 모델이 대중적 시선을 받고 있다. 그런 가운데 최근 전문가들은 단순히 수 천억개의 파라미터를 동원한 거대 언어 모델의 범주를 뛰어넘어 별도의 외부 지식으로 그 기능을 강화한 모델이나, 다양한 모달리티를 결합한 모델 등을 연구하고 있다.
또 다양한 분야, 즉 음악이나 로봇, 프로그래밍 등 자유로운 크로스 모달이 가능한 방식도 모색하고 있다. 한국전자통신연구원의 이용주 책임연구원은 이를 크게 △더욱 효율적인 AI, △멀티 모달 AI, △창작AI 등으로 구분, 설명하고 있다. 기존의 유사한 연구 중에서도 이는 가장 체계적이고 합리적인 접근방식으로 눈길을 끈다.
파라미터 벗어나 ‘외부 검색’으로 열린 지식 반영
이에 따르면 기존 언어 모델은 수천억 개의 파라미터를 활용하여 모델링하고 있다. 그러나 최근에는 외부 지식 또는 필요한 또다른 지식을 대거 추가하는 초거대 언어 모델들이 등장하고 있다.
전자통신연구원에 따르면 이른바 ‘외부 검색 등을 통해 열린 지식을 반영하는 언어 모델’은 이미 구글, 딥마인드, 오픈AI 등에 의해 상당한 진척을 보이고 있다.
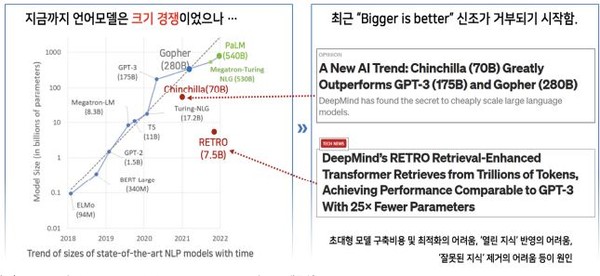
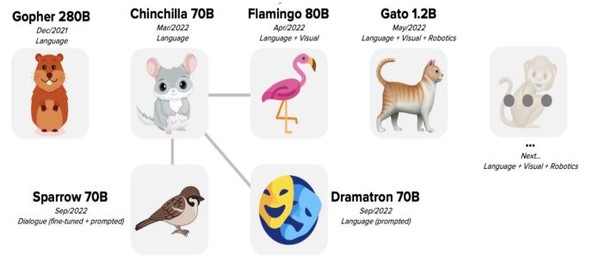
우선 딥마인드의 ‘친칠라(Chinchilla)’ 모델은 모델 크기와 토큰 수를 고려한 최적학습에 의한 것이다. 이는 매개변수 증가 비율과 학습 데이터 증가비율을 같게 함으로써 학습의 효율성을 높였다. 그 결과 GPT-3에 비해 파라미터는 1/4 가량 적고, 데이터셋은 4배나 늘릴 수 있었다.
역시 딥마인드의 ‘레트로(RETRO)’는 외부 지식 DB를 활용한 케이스다. 엄청난 규모의 어휘와 정보를 지닌 웹, 책, 뉴스, 위키피디아, 깃허브 등의 외부 정보 검색을 통해 모델의 성능을 개선했다.
오픈AI가 2021년 연말 공개한 웹GPT도 마이크로소프트의 검색 엔진 Bing을 활용, 검색한 내용으로 모델의 입력값을 생성하도록 한 것이다.
또 구글이 ‘REALM’, ‘ByT5’, ‘CANINE’ 등도 비슷하다. ‘REALM’은 언어 모델에 단순히 저장된 지식 대신에 별도의 모델이 어떤 지식을 검색할지 결정하도록 했다. 그 결과 추론을 할 때 검색된 지식을 사용하도록 하는 방법이다. ‘ByT5’는 토큰 단위가 아닌 문자(character)나, 바이트(byte)를 언어 단위로 채택했다. 이를 위해 최소한의 트랜스포머 구조 변경을 통해 성능을 개선한 것이다.
‘CANINE’은 명시적인 분리나 사전이 없이, 각 언어의 문자 자체에서 동작할 수 있도록 단위를 결정했다. 이를 통해 언어단위 표현 결정을 독립적으로 수행할 수 있게 한 것이다.
멀티모달…텍스트 기반 뛰어넘어, 이미지까지 적용
기존의 텍스트 기반의 사전 학습 방식을 뛰어넘어, 텍스트와 이미지를 모두 적용한 멀티모달 사전학습 모델 연구도 활발하다. 최근에 와선 구글과 딥마인드, 메타(페이스북), 알리바바 등이 이같은 멀티모달 AI 연구를 주도하고 있다.
대표적인 멀티모달 모델 사례를 보면 우선 구글의 ‘PaLI’가 대표적이다. 이는 100개 이상의 언어로 학습한 것으로, 시각을 활용한 이미지 분류, 객체 감지, 이미지 캡션, 질의응답, 광학 문자 인식 등 다양한 기능을 통합한 것이다.
역시 구글의 ‘VATT’는 비디오, 오디오, 텍스트를 결합하여 자기지도학습에 기반한 멀티모달 사전학습을 거친 것이다. 비디오 행동인식, 이미지 분류 등 다양한 기능을 할 수 있다.
미국 조지아 공대의 ‘ViLBERT’도 ‘Co-Attention Transformer’ 구조를 이용하여 자연어와 이미지 데이터를 혼합한 기술을 적용한 것이다. 즉 BERT 방식을 이용하여 텍스트와 이미지를 활용하여 ‘VQA’(Visual Question Answering), ‘Image Retrieval’ 등에 응용하고 있다.
마이크로소프트의 ‘UNITER’ 역시 이미지와 텍스트를 결합한 멀티모달 사전학습 모델이다. 이는 이미지 임베더(Image Embedder), 텍스트 임베더(Text Embedder), 멀티 레이어 트랜스포머(Multi-layer Transformer)로 이루어져있다.
딥마인드의 ‘Frozen’는 언어 모델을 통해 시각 정보를 VQA에 적용했으며, ‘Flamingo’는 트랜스포머 기반 700억 개 파라미터 모델인 자사의 ‘친칠라’에 이미지 엔코더를 결합한 것이다.
페이스북의 ‘UniT’는 7개의 태스크를 하나의 유니파이드 모델로 병합하고, 텍스트 입력과 이미지의 입력을 결합한 트랜스포머 구조다.
중국 알리바바도 중국어 버전의 멀티모델 사전 훈련 툴인 M6(Multi-Modality to Multi-Modality Multitask Mega-transformer)을 개발했다.k 이는 300GB 규모의 텍스트와 2TB 규모의 이미지를 통해 모델을 구축한 것이다.

언어, 시․청각 등 다양한 모달리티 결합한 생성으로
초거대 AI 연구는 또 각각의 모달리티별로 자유로운 변화가 가능한 ‘크로스모달’, 즉 창작 AI로 진화하고 있다. 이는 단순한 텍스트의 생성에서부터, 점차 코드나 이미지, 음성, 비디오, 3D 생성으로 확장되고 있다. 특히 막대한 훈련비용을 들여가며, 겨우 언어 모델을 생성하는데 그치기보단, 언어, 시각, 청각 등과 같은 다양한 모달리티를 결합한 생성 연구로 전환하고 있는 추세다.
그 결과 카피라이팅, 코드 제작, 그림/영상 제작, 게임, 미디어/광고, 디자인, 소셜 미디어 등과 같은 다양한 창작활동에 본격적으로 접목될 전망이다.
특히 그 선두 주자라고 할 오픈AI의 달리(DALL-E)1은 소위 벡터 양자화된 ‘가변 오토인코더(VQ-VAE)’를 활용한 코드북 방식을 활용했고, 달리(DALL-E)2는 디퓨전(diffusion) 모델을 활용한 디코더를 점차 활용하게 되었다. 이를 계기로 텍스트-이미지 확산(diffusion)모델을 통해 보다 사실적인 묘사가 가능한 모델들이 출현하게 되었다.
구글은 텍스트 인코더 이후에 텍스트에서 이미지를 변환하는 디퓨전 모델, 초해상화, 디퓨전 모델을 활용하여 최대로 해상도가 높은 이미지를 생성하게 되었다. 그후 메타 AI의‘Make-A-Scene’을 통해 사용자의 스케치가 가능한 연구로 발전했다. 또 ‘Stable Diffusion’과 미드저니(MidJourney)와 같은 본격적인 디퓨전 모델도 확산되고 있다.

최근에는 또 텍스트에서 비디오까지 생성하는 기술도 개발되었다. 메타AI는 ‘Make-A-Scene’의 후속으로 ‘Make-A-Video’를 통해 16개의 64×64 프레임을 생성한 후 초해상화 기법을 적용, 768×768 크기의 5초 동영상을 생성하기에 이르렀다.
또 구글도 ‘Imagen Video’ 및 ‘Phenaki’ 연구를 통해 16개의 24×48 프레임을 생성한 후 7단계의 업스케일링을 통해 초당 24 프레임의 1024×768 비디오를 생성하거나 최대 2분짜리 비디오를 생성하는 수준에까지 이르렀다. “이는 기존의 사전학습 모델을 텍스트 인코더로 활용하거나, ‘T5-XXL’ 크기의 언어 사전학습 모델을 통해 텍스트 인코더를 활용하고, 이후 비디오 디퓨전 모델 방식으로 확장한 사례”라는 설명이다.