1월5일 [AI-①] 디지털 전환 핵심 경쟁력 ‘AI·데이터’에 이어
AI 학습용 데이터란 머신러닝, 딥러닝 등 AI 모델 학습을 위해 활용되는 데이터를 총칭한다. 원본 데이터와 원본 데이터에 활용 목적에 따라 표시 작업을 한 라벨링 데이터를 모두 AI 학습용 데이터라 하며 원본 데이터는 하나지만 라벨링 데이터는 사용 목적에 따라 다양한 형식으로 가공이 가능하다.
한편 AI 학습용 데이터는 원본 데이터와 라벨링 데이터로 구성되는데 원본 데이터에는 이미지, 영상 텍스트, 음성 등이 포함되며 라벵링 데이터는 활용 목적에 따라 구분된다.
AI 학습용 데이터는 목적에 따라 학습 데이터, 검증데이터, 평가 데이터로 구분해 활용되며 이에 학습 데이터로 AI 모델을 학습 → AI 모델 정확도 확인을 위해 검증데이터를 활용해 수정 → 평가 데이터로 성능 평가 진행 등의 과정을 거친다.
학습 데이터는 알고리즘이 학습할 데이터로 모델 학습에 주가 되는 역할을 하며 검증 데이터는 학습 중간에 모델의 예측·분류 정확도를 계산하는 역할을 한다. 또 평가 데이터는 모델이 학습 과정에서 경험하지 못했던 데이터로 학습후 훈련한 모델의 성능을 평가하는 과정에서 사용된다.
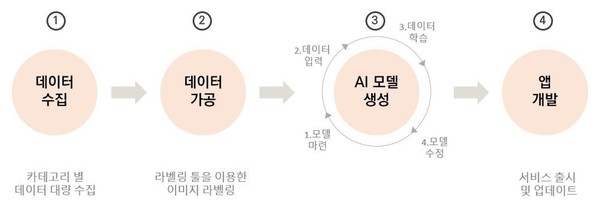
AI 학습용 데이터의 구축부터 AI 서비스 출시 과정까지를 살펴보면 먼저 AI 모델생성을 위한 데이터 수집 또는 제작을 통해 학습용 데이터를 구축하는 과정을 거쳐 데이터의 종류에 따라 원하는 AI 학습 모델을 제작하기 위해서 편향과 노이즈를 제거하고 속성 표시 작업을 진행한다.
그다음으로 정제된 데이터로 AI를 학습시키고 문제 발생시 모델을 수정하는 과정을 거쳐 최종 모델을 생성한다. 이후 소비자에게 제공할 수 있는 정도의 서비스 정확도가 나오면 본 서비스를 출시한다.
AI 학습용 데이터 구축에는 다양한 방법이 있으며 상황과 비용적 이슈를 고려해 최적화된 방식으로 구축한다.
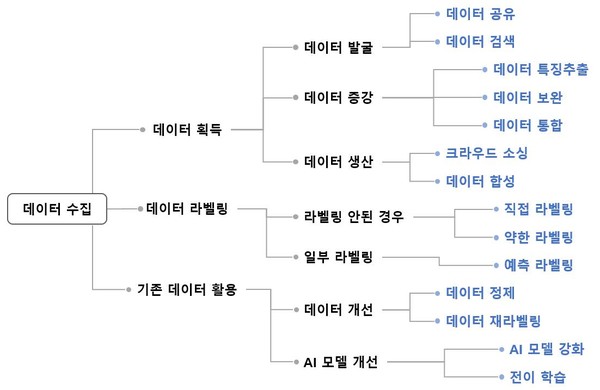
데이터가 없는 경우 크라우드 소싱이나 데이터 합성을 통해 신규 데이터를 만들고 기존 데이터가 있는 경우 기존 데이터를 보완, 통합하거나 재가공해 데이터를 획득한다.
데이터 라벨링은 사람이 데이터를 직접 라벨링하는 방식으로 자동화 기술을 통한 대용량의 라벨링 방법 활용이 가능하다. 라벨링 방식에 따라 비용과 시간 결과물의 품질 차이가 발생 할 수 있다.
또 기존 데이터의 편향·노이즈 제거, 재라벨링 등 품질 향상을 통해 기존 데이터를 정제하거나 이미 학습된 AI 모델을 재학습 시키는 방식으로 AI 모델을 개선할 수 있다.
AI 학습용 데이터 구축 단계별 인력 명칭과 역량을 살펴보면 먼저 1단계에는 데이터 라벨러 및 데이터 수집가 등이 포함되는 데 크라우드 소싱, 아르바이트 등의 방식으로 기업에서 고용하는 단계다. 별도의 기본 역량은 없으며 IT에 대한 기본적인 이해와 MS 제품을 사용하는 수준이며 기본적인 데이터 도구 학습·사용 능력을 갖추고 있다.
라벨링하는 기준을 명확하게 인지하고 장시간 일관되게 데이터에 적용해야 하므로 인내력과 일관성이 중요하다.
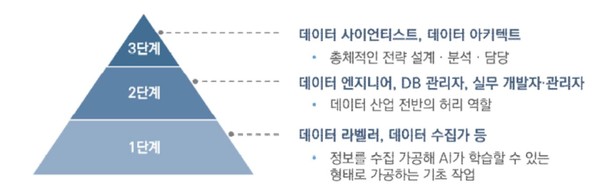
2단계에는 데이터 엔지니어, DB 관리자, 실무 개발자·관리자 등이 있는데 많은 기업이 계약직 이상의 일자리를 통해 필요로 하는 단계다.
통계적인 관점에서 대용량 데이터를 직관적으로 판단하고 활용 가능한 데이터인지 올바른 성능 평가를 할 수 있는 역량을 갖추고 있다. 또 데이터 추출·관리, AI 모델의 구현·학습·성능 평가를 할 수 있는 역량도 가춰야 한다.
3단계에는 데이터 사이언티스트, 데이터 아키텍트 등이 있는데 AI 기업, 데이터 기업에서 정규직으로 채용해 집중적으로 육성하는 단계다.
데이터에 대한 이해뿐만 아니라 AI에 대해서도 알고 있으며 데이터만으로 어떤 AI를 구축할지 분석할 수 있는 인력들이 이 단계에 포함된다. AI 모델의 근간이 되는 수학, 통계, 확률에 대한 탄탄한 기초와 깊은 이해가 가장 중요한 역량이다.
다음에는 국내 AI 학습용 데이터 구축 방법 분석에 대해 알아 보고자 한다.